Padding Oracle attack against Telegram Passport
Category: writeupsTags: crypto
Since the Telegram Passport came out, I tried to analyze its protocol to understand whether the encryption of users’ data was strong and properly implemented.
UPDATE: It seems that the Telegram Passport specification is written “superficially” and I assumed the data was right-padded.
It’s left-padded instead, so the content of this post is based on a wrong interpretation of them.
This attack doesn’t apply to Telegram Passport.
The specification describes a centralized encrypted storage where “users can upload their documents once, then instantly share their data with services that require real-world ID (finance, ICOs, etc.)”. If you want to read the full specification you can check Telegram’s documentation.
This blog post will focus on the custom padding, designed by Telegram, used together with AES-CBC, and how it can be abused. This flow is used when the Telegram client shares the user document with the third-party service.
Note: This post will not describe a direct vulnerability against Telegram services.
Telegram Passport workflow
The specification involves 3 entities:
- the end users
- the Telegram Passport server, where the users’ documents are stored
- the third-party service (e.g. a Telegram bot), that will receive the documents
As mentioned, I focused my attention on item number 3, and on the decryption mechanism that third-party services need to implement in order to be able to retrieve users’ data from Telegram. The part of specification that defines this interaction is below:
Decrypting data
To decrypt the received data, first, decrypt the credentials contained in EncryptedCredentials.
- Decrypt the credentials secret ( secret field in EncryptedCredentials) using your private key (set OAEP padding option, e.g.
OPENSSL_PKCS1_OAEP_PADDINGin PHP)Use this secret and the credentials hash ( hash field in EncryptedCredentials) to calculate credentials_key and credentials_iv as described below:
credentials_secret_hash = SHA512( credentials_secret + credentials_hash ) credentials_key = slice( credentials_secret_hash, 0, 32 ) credentials_iv = slice( credentials_secret_hash, 32, 16 )Decrypt the credentials data ( data field in EncryptedCredentials) by AES256-CBC using these credentials_key and credentials_iv. IMPORTANT: At this step, make sure that the credentials hash is equal to
SHA256( credentials_data )- Credentials data is padded with 32 to 255 random padding bytes to make its length divisible by 16 bytes. The first byte contains the length of this padding (including this byte). Remove the padding to get the data.
The user document, called “credentials data” in the spec, is encrypted with AES256-CBC. This mode of operation is malleable in a way that, during decryption, a one-bit change to the ciphertext causes complete corruption of the corresponding block of plaintext, but it inverts the corresponding bit in the following block of plaintext while the rest of the blocks remain intact.
This property makes CBC-mode implementation vulnerable to padding oracle attacks. More specifically, knowing whether or not a given ciphertext produces plaintext with valid padding is ALL that an attacker needs to break a CBC encryption. If you can feed in ciphertexts and somehow find out whether or not they decrypt to something with valid padding or not, then you can decrypt ANY given ciphertext.
If you want to learn more about padding oracle attacks, read this awesome article
Personally I was really interested and surprised by Telegram’s choice for the padding. It’s not a standard padding like PKCS#5 or PKCS#7 but instead it was a custom padding: the original data is padded with an arbitrary number of random bytes, between 32 and 255, to make the payload’s size a multiple of 16 (the AES block size); the first byte of the padding contains the number of bytes that have been used for padding, including itself.
The Scenario
The specification is not really clear but from the clients’ source code we can see what is going on. A Python representation of how the padding works is below:
def pad(s):
len_s = len(s)
bytes_to_add = 32 + random.randrange(0, 255 - 32 - BLOCK_SIZE)
bytes_to_add += BLOCK_SIZE - (bytes_to_add + len_s) % BLOCK_SIZE
return s + chr(bytes_to_add) + os.urandom(bytes_to_add - 1)
We don’t care much about how many padding bytes there are. The thing that is precious is the “magic byte” that contains the lenght of the padding.
The EncryptedCredential is an encrypted JSON object that contains 3 field: data, hash and secret.
datacontains a base64-encoded encrypted JSON-serialized datahashcontains a base64-encoded data hash for data authenticationsecretcontains a base64-encoded secret, encrypted with the bot’s public RSA key
Ex.
{
"data": "[base64]"
"hash": "[base64]"
"secret": "[base64]"
}Before going further, please note that Telegram mandates developers to check that the SHA-256 hash of the decrypted padded data matches the hash provided in the JSON payload, effectively making the padding oracle attack infeasible. However, if third-party developers don’t do this check, this attack is still valid.
Note that a JSON object always starts with a { character and ends with a }.
In our scenario the third-party service (e.g. a Telegram bot) that will receive this encrypted JSON object will perform the following steps:
- Decrypt the
secretpayload with the bot private key - Calculate
keyandivlike the specification above - Decrypt the
datapayload - Unpad the
dataplaintext:- Search for the first
}character in the plaintext - Read the next byte as “padding byte”
- Check if the padding length match the value of the “padding byte”
- Report a padding error if there isn’t a
}character or if the padding length don’t match
- Search for the first
- Read the JSON
data. Report an encoding error if the JSON is not valid, report success otherwise
Performing the attack
A standard padding oracle attack against PKCS#5 starts by bruteforcing the right-most byte of the cyphertext until the padding is correct, which means that the decrypted plaintext ends with 0x01.
In our case we can’t perform the attack this way. The last N byte are random bytes so bruteforcing them won’t give any useful result. Also, since we are going backwards, sooner or later we will modify the block of cyphertext that contains the “padding byte” and we will corrupt all the block since CBC malleability acts on the next block.
The approach I used instead was bitflipping (XORing with 255) byte-by-byte the ciphertext from left to right.
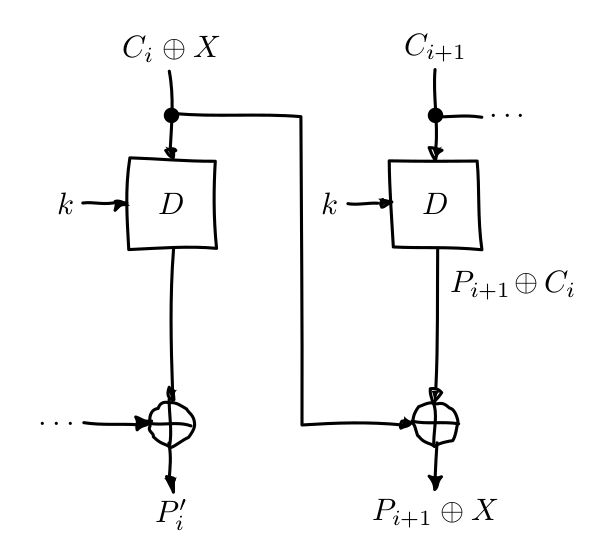
Starting from the cyphertext left-most byte, bitflip it so the first plaintext block will be corrupted but the first byte in the second plaintext block will be bitflipped as well.
This way we will corrupt the actual JSON data in the current block but when we hit the } character in the next one the service will report a padding error.
This approach is prone to false-positives. For example, think of a case where the corrupted data returns a new } character that accidentally is followed by the exact padding length; when the service reports a padding error, we will perform another test on the same byte XORing it with 127 instead. If the service returns a padding error again we can be pretty confident that we hit the “padding byte”.
With this mechanism we can learn information about the padding length and the payload length, and we know where to start for the actual padding oracle attack.
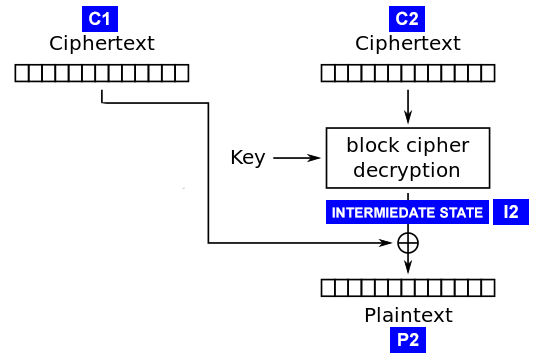
Let’s suppose that the plaintext is formed as follows:
- the
}character is in the 20th position - the padding-length byte is in the 21th position
To learn the plaintext value in the 19th position we need to get its intermediate value and XOR it with the cyphertext value at that position.
To get the intermediate value you must find the value v in C1 that XORed with I2 gives a } in the 19th position and the right “padding byte” in the 20th one.
v ⊕ '}' = I2[19]
C1[19] ⊕ I2[19] = P2[19]
We can bruteforce the 19th and 20th bytes in the plaintext by bruteforcing the 3rd and 4th bytes in the cyphertext (19 - 16 = 3), supplying to the padding oracle 2 blocks:
- the first block contains null bytes (
\x00) except for bytes 3 and 4, which are the ones we want to bruteforce - the second block contains the encrypted bytes we want to decrypt
Once we learn the value for the 19th position we can repeat the same process on the 18th-19th bytes and so on obtaining all the plaintext*.
As we noticed above, this approach is also prone to false-positives, so once we find a valid value v we perform a verification step by replacing the null bytes in the first block with \xff.
* Unfortunately in our scenario we can’t decrypt all the plaintext since the first block is XORed with the IV that is out of our knowledge. However, considering that the first block starts with {"data":" + base64_of_image_header, we can likely bruteforce it.
“Show me the code!”
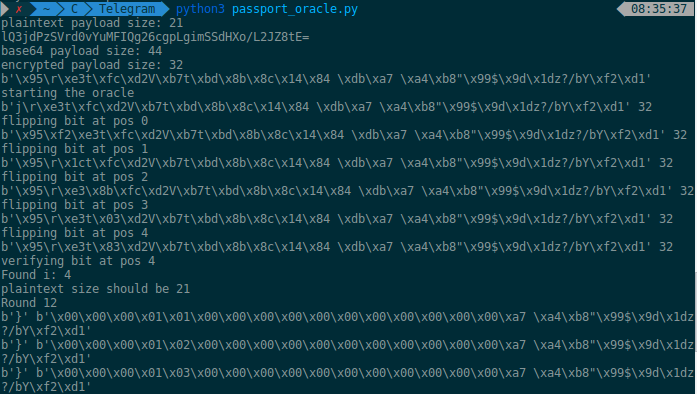
While I was researching this I wrote a simple server implementing our defined scenario, and a client performing the padding oracle attack demonstrating our discovery.
The code is just a PoC, it’s pretty bad and nowhere near a stable version but you can download it here.
Run the server with python2 tpassport.py and then the client with python3 passport_oracle.py.
You may need to resolve some dependency to run the scripts.
Conclusion
It doesn’t matter what type of padding you use along with CBC-mode, there always is an approach that can be used in a padding oracle scenario to decrypt the cyphertext.
If you plan to use CBC, always perform integrity checks before the decryption in a encrypt-then-MAC fashion and, if possible, use an HMAC to authenticate the data. If possible don’t use CBC at all and prefer an AE/AEAD mode like GCM.
Last but not least important: Don’t roll your own crypto™
I would like to thank: